Linux C编程
C语言的源代码文件是一个普通的文本文件,但扩展名是c.而且源代码文件是不能直接执行的,需要编译,编译后的可执行文件只能在指定操作系统下运行.
Linux编译后的可执行程序只能在linux运行,windows编译后的程序只能在windows下运行
64位的linux编译后的程序只能在64位linux下运行,32位linux编译后的程序只能在32位的linux运行.
64位的windows编译后的程序只能在64位windows下运行,32位windows编译后的程序可以在64位的windows运行.
头文件包含
include有两种写法
#include <文件名>,如果文件在系统目录下,那么需要用<>
#include “文件名”,如果文件在当前目录下,那么用””
System系统调用
在使用system之前需要包含stdlib.h这个头文件,system主要的功能是通过程序执行另外一个程序
system("命令"); |
如果在命令行执行一个程序,那么这个程序的调用者就是操作系统,如果在代码中通过system执行一个程序,那么这个程序的调用者就是自己写的代码本身.
C语言所有的库函数调用,只能保证语法是一致的,但不能保证执行结果是一致的,同样的库函数在不同的操作系统下执行结果可能是一样的,也可能是不一样的。
POSIX标准
POSIX是一个标准,只要符合这个标准的函数,在不同的系统下执行的结果就可以一致。
Unix和Linux很多库函数都是支持POSIX的,但windows支持的比较差。
如果将unix代码移植到linux一般代价很小,如果把windows代码移植到unix或者linux就比较麻烦.
C语言处理过程
C代码编译成可执行程序经过4步:
1)预处理:宏定义展开、头文件展开、条件编译等,同时将代码中的注释删除,这里并不会检查语法
2)编译:检查语法,将预处理后文件编译生成汇编文件
3)汇编:将汇编文件生成目标文件(二进制文件)
4)链接: C语言写的程序是需要依赖各种库的,所以编译之后还需要把库链接到最终的可执行程序中去
预处理:
gcc -E hello.c -o hello.i |
编译:
gcc -S hello.i -o hello.s |
汇编:
gcc -c hello.s -o hello.o |
链接:
gcc hello.o -o hello |
查看程序所需动态库:
ldd hello //linux |
交换文件说明:
1) vi写文件,没有保存就关闭,自动生成一个后缀为. swp交换文件, 保存了之前写的内容
2)先恢复,再删除.swp交换文件
vi -r {your file name} //恢复 |
常量和变量
关键字
C的关键字共有32个
数据类型关键字(12个)
char, short, int, long, float, double,unsigned, signed, struct, union, enum, void
控制语句关键字(12个)
if, else, switch, case, default,for , do, while, break, continue, goto, return
存储类关键字(5个)
auto,extern,register, static,const
其他关键字(3个)
sizeof, typedef, volatile
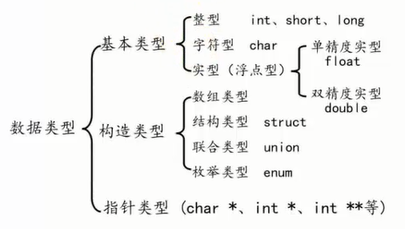
数据类型
数据类型的作用:编译器预算对象(变量)分配的内存空间大小
常量
- 在程序运行过程中,其值不能被改变的量
- 常量一般出现在表达式或赋值语句中
变量
- 在程序运行过程中,其值可以改变
- 变量在使用前必须先定义,定义变量前必须有相应的数据类型
标识符命名规则:
标识符不能是关键字
标识符只能由字母、数字、下划线组成
- 第一个字符必须为字母或下划线
- 标识符中字母区分大小写
变量特点:
- 变量在编译时为其分配相应的内存空间
- 可以通过其名字和地址访问相应内存
声明和定义区别:
- 声明变量不需要建立存储空间,如: extern int a;(a不能赋值)
- 定义变量需要建立存储空间,如: int b;
- -般的情况下,把建立存储空间的声明称之为“定义”,而把不需要建立存储空间的声明称之为”声明”.
进制
C语言如何表示相应的进制数
| 十进制 | 以正常数字1-9开头,如123 |
|---|---|
| 八进制 | 以0(零)开头,如0123 |
| 十六进制 | 以0x开头,如0x123 |
| 二进制 | C语言不能直接书写二进制数 |
计算机内存数值存储方式
在计算机系统中,数值一律用补码来存储。
原码:
最高位为符号位:0代表正数,1代表负数
原码存储导致2个问题:
- 0有两种存储方式
- 正数和负数相加结果不正确
反码:
反码是为了算补码.正数的原码和反码是一样的,负数的反码在原码基础上,符号位不变,其它位取反(0为1,1变0 ).
反码存储导致1个问题:
- 0有两种存储方式
补码:
正数的原码,反码,补码都一样
负数的补码为其反码加1
十进制数,站在用户角度看,原码;二进制,八进制,十六进制,要站在计算机角度看,补码.
原码求补码:
- 正数原,反,补码均相同
- 负数原码最高位不变,其他位取反得反码
- 反码加1得补码
补码求原码(同上面类似):
- 正数原,反,补码均相同
- 负数补码最高位不变,其他位取反得反码
- 反码加1得原码
|
上面程序运行结果如下:

按照十六进制转十进制,0x81等于129而不是-127
分析:
- 0x81在计算机角度看来应为补码存储,其二进制形式为10000001
- 输出%d即输出十进制数,十进制数在用户角度为原码
- 由(1)(2)知,该程序即将0x81的补码转换为原码
- 其原码为11111111,即-127
有符号和无符号的区别:
- %d,默认以有符号的方式打印
- %u,默认以无符号的方式打印
- 有符号,最高位是符号位,如果是1代表为负数,如果为0代表为正数
- 无符号,最高位不是符号位,是数的一部分,无符号不可能是负数
数据类型范围:
char 1个字节

数值越界:
通过以下代码解释
|
运行结果如下:

sizeof关键字
- sizeof不是函数,所以不需要包含任何头文件,它的功能是计算一个数据类型的大小,单位为字节
- sizeof的返回值为size_ t
- size_t 类型在32位操作系统下是unsigned int,是一个无符号的整数
|
运行结果如下:
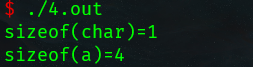
%d,%o,%x,%u等均以四个字节形式打印.
short占两个字节,short a;与short int a;等价.
| 数据类型 | 占用空间 |
|---|---|
| short (短整型) | 2字节 |
| int (整型) | 4字节 |
| 1ong(长整形) | Windows为4字节,Linux为 4字节(32位),8字节(64位) |
| long long (长长整形) | 8字节 |
字符型变量
字符型变量用于存储一个单一字符,在C语言中用char 表示,其中每个字符变量都会占用1个字节。在给字符型变量赋值时,需要用一对英文半角格式的单引号(‘ ‘)把字符括起来。
字符变量实际上并不是把该字符本身放到变量的内存单元中去,而是将该字符对应的ASCII 编码放到变量的存储单元中。char 的本质就是一个1 字节大小的整型。
使用
man ascii |
查看ASCII码
转义字符
字符在单引号内,原则上’ ‘内部只有一个字符,转义字符除外,不能char a=’abc’
转义字符由反斜杠\组成的多个字符
例子
|
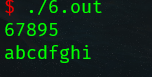
浮点型(实型)
实型变量也可以称为浮点型变量,浮点型变量是用来存储小数数值的。在C语言中,浮点型变量分为两种:单精度浮点数(float)、双精度浮点数(double),但是double型变量所表示的浮点数比float 型变量更精确。
| 数据类型 | 占用空间 | 有效数字范围 |
|---|---|---|
| float | 4字节 | 7位有效数字 |
| double | 8字节 | 15~ 16位有效数字 |
float存储不准确
|

类型限定符
| 限定符 | 含义 |
|---|---|
| extern | 声明一个变量,extexn 声明的变量没有建立存储空间。extern int a; |
| const | 定义一个常量,常量的值不能修改。const int a 10; |
| vo1atile | 防止编译器优化代码 |
| register | 定义寄存器变量,提高效率。 register是建议型的指令,而不是命令型的指令,如果CPU有空闲寄存器,那么register就生效, 如果没有空闲寄存器,那么register无效。 |
输出
字符串常量与字符常量的不同:
‘a’为字符常量,”a”为字符串常量

每个字符串的结尾,编译器会自动的添加一一个结束标志位’\0’,即”a” 包含
两个字符’a’和’\0’。
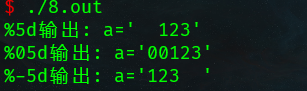
%%在屏幕输出一个%,后面的d也会输出
%5d,以5个字符输出,没有的字符以空字符填充,默认是右对齐
%05d,以5个字符输出,没有的字符以0填充,默认是右对齐
%-5d,以5个字符输出,没有的字符以空字符填充,-代表指定为左对齐
0和-不能同时使用
printf
遇到”\0”停止
puts()
|

fputs()
|

输入
scanf
scanf()的缺陷,不做越界检查,不允许有空格
|
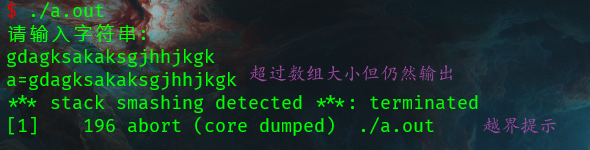
gets()
gets()从键盘读取字符串,放在指定的数组
gets()允许有空格,不做越界检查,此函数不安全
fgets()
|
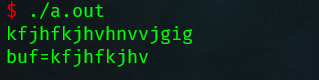
fgets()允许有空格

当不足sizeof(buf)-1,会把换行符读进去
|

输入字符
|
上面这个程序看似简单,结果为a=c,b=d,其实不然,结果如下:
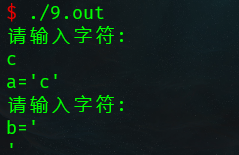
无需输入d直接出结果
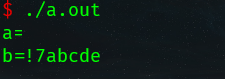
原因:
当用户输入字符时,编译器默认把输入的内容先放在一块内存中(缓冲区) , scanf()自动在缓冲区读内容(只读一个字符).第一次输入时输入了c\n(回车),scanf取走了c,留下\n还在缓存区,第2次scanf ,由于缓冲区还有内容,所以直接取内容,无需再输入
所以,上面的程序可以这样写
|
输入字符串
|
运行结果如下:
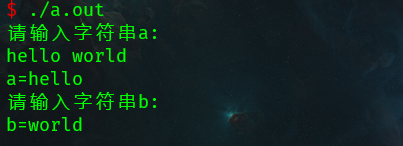
原因:
当输入hello world时,第一个scanf取走第一个空格前的字符串,即hello;第二个scanf取第一个空格后第二个空格前的内容,\\n不取
switch语句
|
goto语句
goto(只能跳转到同一作用域)任意地方都能使用,无条件跳转,不能滥用,代码会很乱
|
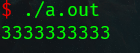
类型转换:
1.隐式转换
double a; |
2.强制类型转换
int a=10; |
转换原则:占用内存字节数少(值域小)的类型,向占用内存字节数多(值域大)的类型转换,以保证精度不降低。
3.浮点型和整型打印问题
a)不要直接通过%d,打印一个浮点型变量,得不到想要的结果,要想得到结果,强制类型转换
double a = 11.11 ; |
b)不要直接通过%f或%lf,打印一个整型变量,得不到想要的结果,要想得到结果,强制类型转换
数组
- 数组内部的变量或数组,不初始化,它的值为随机数
- 部分初始化,其它自动初始化为0
0~2(前3个元素)分别为1,2, 3, 其 它初始化为0
int a1[10] = {1, 2, 3}; - 数组全部元素初始化为0
int a2[10] = {0} ; - 如果定义时同时初始化,第1个[]内部可以不写内容
编译器会根据用户初始化的元素来确定数组的大小
int a3[]={1,2,3,4,5,6,7,8,9,10}; - 如果第1个[]内容不写,必须初始化,否则语法错误
数组名
- 数组名是常量,不能修改
- 数组名是数组首元素地址
|

二维数组
内存中没有多维,只有一维,多维数组是特殊的一维数组
//如果定义时,同时初始化,第1个[]可以不写内容 |
字符数组
- C语言没有字符串类型,用字符数组模拟
- 字符串一定是字符数组,字符数组就不一定是字符串
- 如果字符数组以字符’\0’ (‘\0’等级于数字0)结尾,那么这个字符数组就是字符串
//1、C语言没有字符串类型,用字符数组模拟 |
|
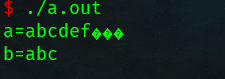
字符数组初始化(常用)
char a[10]="abcde";//最多写9个字符,留一个放结束符 |

\0后面最好不要跟数字,有可能组成转义字符
|
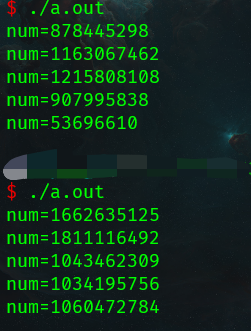
函数的调用:产生随机数
当调用函数时,需要关心5要素:
- 头文件:包含指定的头文件
- 函数名字:函数名字必须和头文件声明的名字一样
- 功能:需要知道此函数功能后再调用
- 参数:参数类型要匹配
- 返回值:根据需要接收返回值
|
函数
strlen
strlen需要使用返回值,返回值就是字符串的长度,从首元素开始,到结束符为止的长度,结束符不算(遇到’\0’结束)
strcpy
拷贝原理:从首元素开始,到结束符(\0)为止的长度
strncpy
可以把”\0”拷贝过去,但是”\0”后面的就不能了

